GAN : AI Creating a Whole New Creature. Is It a Warning Sign?
GAN의 이미지 형성 / 재형성 부분을 공부하면서 Mind blown 된 부분.
CCTV에서 화질이 따라와주지 않을때 얼굴 모양을 복귀로 시작하여,
마지막 부분은 아래와 같이 비슷한 이미지를 더 주어졌을때 이를 Reference 하여 얼굴을 만들어 갈 수도 있다는 GAN.
일단 너무나 재밌게 읽은, 카카오의 블로그
http:// www.kakaobrain.com/blog/57
Super Resolution GAN에 대한 블로그 (정말 많이 도움되는 글)
hoya012.github.io/blog/SIngle-Image-Super-Resolution-Overview/
Single Image Super Resolution using Deep Learning Overview
Single Image Super Resolution에 대해 간단한 소개, 딥러닝을 적용하는 방법들에 대한 소개를 다루고 있습니다.
hoya012.github.io
추가 학습 자료
이번 학습을 통해 Super Resolution 문제를 해결하는데 흥미가 생겼다면, 아래 영상 자료를 통해 여기서 다루지 못한 자세한 내용을 학습해 보세요. SRGAN의 경우 모두의연구소 김승일 소장님께서 직접 설명해 주십니다😆
참고 자료: PR12 - SRCNN
참고 자료: PR12 - SRGAN
참고 자료: EDSR
참고 자료: 딥러닝 Super Resolution 어디까지 왔니?

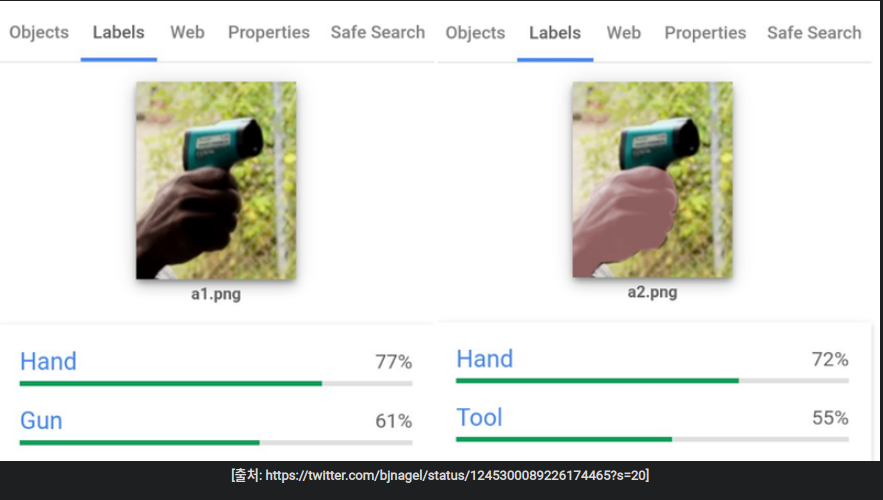
백인의 손을 보여주면, tool로 인식하고,
흑인의 손을 보여주면 잡은 물건을 gun으로 인식한다.
인공지능을 배우는 부분에 있어서
이러한 새로운 기술을 어느 정도까지 받아들이고, 어느 정도 까지는 Block하고 Control해야 하는 부분이 가장 AI에서의 핵심 논쟁 거리가 될 것 같다.
예를 들어서, 최근의 이루다의 여성, 노약자 등을 혐오하는 발언건만 보아도, 인터넷을 떠들썩하게 만들었다.
하지만, 간단하게 생각해 보자면, 그냥 기계가 이전에 학습 된 것에 의해서 그러한 혐오스러운 발언을 한 것으로 볼 수도 있지만,
이번 GAN의 이미지 형성에 있어서는 사실 많이 놀랬다.
이러한 New technology - AI와 Social Justice를 관련해서
기술회사의 얼굴인식 기술을 정부에 판매하는 걸 금지해야 한다고 주장하고 있는 University of Sydney 의 Roman Marchant 교수님의 주장을 반영한 기사도 아주 재미있게 볼 수 있겠다.
기사 원본 링크:www.cmo.com.au/article/658978/black-box-algorithms-should-applied-human-outcomes/
Data scientist: Black box algorithms should not be applied to human outcomes
Algorithms must be transparent, accountable, and interpretable, says University of Sydney data science lecturer and expert
- VANESSA MITCHELL (CMO)
- 22 MARCH, 2019 08:02

Where human outcomes are the goal, black box algorithms should not be allowed, a data scientist from the University of Sydney believes.
Speaking to CMO ahead of the University’s Ethics of Data Science conference next week, Dr Roman Marchant, lecturer and data scientist at the University of Sydney, said that while it is common practice for big companies to use black box algorithms to come up with an output, they should not be applied to the lives of humans.
This is because you cannot ‘open’ the black box and discover how the algorithm is coming up with the outcomes it does, so it is not transparent, accountable, or interpretable, he said.
알고리즘이 가져오는 결과를 사람이 인식할 수 없기 때문에 위험하다고 이야기
“It is common for companies to use black box algorithms, otherwise known as deep learning or neural networks, and spit out an output,” Dr Marchant said. “We do use them for some problems, but it’s very tricky to use them on human data, and we are completely against using them for when the result affects the lives of humans, because you cannot open the box and uncover what the algorithm is doing in the background.
“The type of problems where we do apply these models is in applications where no humans can be affected, such as for automated machinery and so on. But, when it comes to humans, we believe these models shouldn’t be allowed.”
While data and its analysis to improve the customer journey and personalisation is key to marketing now, it is far from the silver bullet many marketers believe it to be, as most data contains inherent bias.
Related: Why bias is the biggest threat to AI development
Beware of AI inherent biases and take steps to correct them
According to the University of Sydney, algorithms are a fundamental tool in everyday machine learning and artificial intelligence, but experts have identified a number of ethical problems. Models built with biased and inaccurate data can have serious implications and dangerous consequences, ranging from the legal and safety implications of self-driving cars and incorrect criminal sentencing, to the use of automated weapons in war.
READ MOREHow AI and voice are perpetuating gender stereotypes – and what you can do about it
Before data is used, Dr Marchant advised it be evaluated by an inter-disciplinary team to ensure it is not full of errors, both for the sake of not stereotyping, but also to improve the customer experience.
“The models that are built are very generic and could be used for what outcome you want. All the models are fairly similar, except for the response variable. But there is a concern around biased data, and most companies don’t know what the exiting bias is in the data,” he explained.
“For example, we all have the right to be offered the same product. Usually you wouldn’t discriminate and only offer a product to a certain subset of the population. However, if a data set has an internal bias that males are more likely to buy a product than females, you may end up only marketing that product to men, even though perhaps all your marketing to date has been aimed at men, which then means only men are buying it, which affects the data."
Context around the data is very important, Dr Marchant continued. "Companies need to be able to quantify and correct that bias, which is tricky to do," he said. “To do so, we have to consider the decisions that have been made in the past, to take into account when building the models.

READ MOREHow AI-powered virtual employees will transform customer experience
“Companies must start taking into account other explanatory variables, and they need to be constantly revising models and thinking about what they are doing. Casual effects need to be uncovered, not just correlations and predictions with black box models."
This is why transparency so a third party can assess what algorithm company is using with personal data is vital. "Interpretability means the algorithm needs to be understandable, to enable someone to understand why the algorithm came up with the prediction it did. It means you can make the algorithm accountable for existing problems, like bias,” Dr Marchant said.
“This is not only for the protection of a customer, it also means you can open the box and understand how an algorithm is coming up with predictions and therefore understand your customer in a better way."
알고리즘이 주는 결과가 왜 그렇게 나왔는지 해석과 이해 가능해야한다는 것.
반대로 말하면, 이해되지 않는 결과가 오히려 사회를 혼란 스럽게 만들 수 있다는 것?
The University of Sydney also recommends companies use one of the multiple institutes and data centres, like The Gradient Institute for example, or an internal team of research engineers who can consult with third parties to analyse and study algorithms used, the way they are making decisions, and extract patterns from the data to indicate whether the data is fair or not.

READ MOREHow Best Buy shifted from being retail-led to customer relationship driven
“Ultimately, if a big company has a lot of data and using it to make decisions, they should have an internal team that does that, plus an external data team to evaluate that everything is transparent and done according to law," Dr Marchant said.
The government also has a responsibility to work on laws that protect both companies and users to allow and relieve conflicts around using data, Dr Marchant said. As a step forward, he noted the Human Rights commission of Australia has already assembled a group to examine how AI affects human rights.
Follow CMO on Twitter: @CMOAustralia, take part in the CMO conversation on LinkedIn: CMO ANZ, join us on Facebook: https://www.facebook.com/CMOAustralia, or check us out on Google+:google.com/+CmoAu