싸이킷런- Train & Prediction 헷갈렸던 부분 정리
파이썬에서의 주요 기능중의 하나인 사이킷런
N231에서 배운 이론들을 실제로 가지고 와서 직접 실행 해부는 부분이라서 아주 흥미롭게 진행했다.
그런데 내가 가장 헷갈려하던 x & y 축 부분에 대해서 이번 F-9에서 설명이 나와서 이부분은 한번 집고 넘어가고자 다시 정리하게 되었다.
[1] 내가 가장 헷갈린 부분이
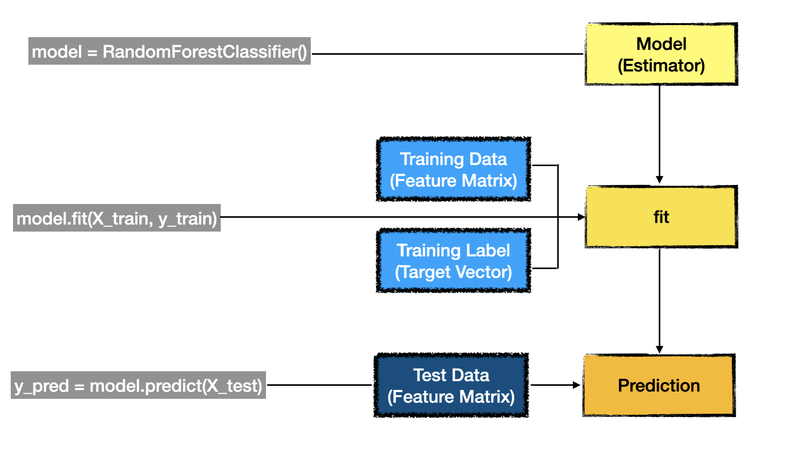
아래에서 x & y 값 넣어서 마지막 prediction 하는 부분에서 왜 다른 값을 넣어서 하지? 라는 부분에서 많이 헷갈렸었는데,
1) 훈련 사용되는 데이터 (특성 행렬)과 예측 prediction 하는 데이터 (특성행렬)에 같은 값을 넣게 되면 똑같은 시험 문제지로 교육을 하고 테스트하는 것과 동일하기 때문에 정확도가 100%밖에 나올 수 없다는 것!
-> 그러하여, 아래의 오른쪽 그림과 같이 훈련에 쓰인느 데이터와 Prediction할때 데이터는 다른 데이터를 넣어줘야 한다는 것!

[2] 두번째로는 데이터를 train & test data를 분리하기 위해 train_test_split() 사용하는 부분
아래와 같이 넣어주는 (train, label , 테스트 값 (여기선 20%), 시험 섞어주는 정도(random_state=42))로 아래와 같이 사용할 수도 있지만!
from sklearn.model_selection import train_test_split
result = train_test_split(X, y, test_size=0.2, random_state=42)
훨씬 더 눈에 깔끔하게 unpacked된 방법으로 아래와 같이 사용할 수도 있다는 것!
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
많이 사용해봐야지 제대로 알겠지만, 이 정도로 만족!