Scikit Learn의 Pipeline은 무엇일까?
LMS의 E9-4부분을 진행하다가
[E9-4] 두번째 동영상 Software Library APIs에서 Pipeline 설명을 하는데 이부분이 궁금해져서 조금 파봤습니다.
동영상 참고:
www.youtube.com/watch?v=WCEXYvv-T5Q&feature=emb_title
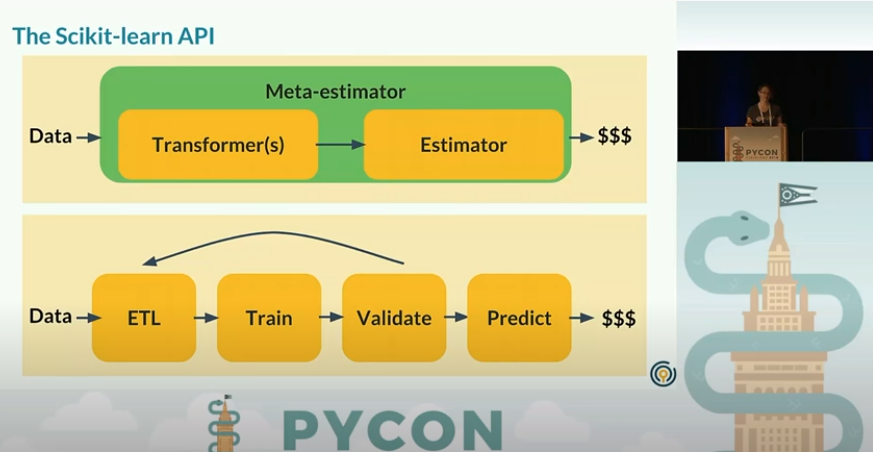


위와 같은 방식으로 일단 pipeline에 대한 메인 포인트를 잡았고,
Pipeline의 정의는
pipeline은 여기서 목적은
Cross-validate 될 수 있는 많은 step들을 한번에 모아서 다른 parameter설정들을 가지고 한번에 할 수 잇다는 것이다.
LMS 노드에서는 Pipeline작업을 transform과 estimate을 모두 수행 이후에 pipeline으로 묶어서 검증을 수행한다고 하는데,
사실상 위에 동영상에서는 pipeline을 활용해서 한번에 모든걸 처리한다고 이야기가 되는 것 같다.
"예시 답안2: 사이킷런은 파이썬 기반 머신러닝 라이브러리로 Scipy 및 NumPy 와 비슷한 데이터 표현과 수학 관련 함수를 갖고 있습니다. 일반적으로 머신러닝에서 데이터 가공(ETL)을 거쳐 모델을 훈련하고 예측하는 과정을 거치는데 ETL부분은 ScikitLearn의 transformer()를 제공하고, 모델의 훈련과 예측은 Estimator 객체를 통해 수행되며, Estimator에는 각각 fit()(훈련), predict()(예측)을 행하는 메소드가 있습니다. 모델의 훈련과 예측이 끝나면 이 2가지는 작업을 Pipeline()으로 묶어 검증을 수행합니다. (feat. LMS 노드에서 언급 된 부분)"
SKlearn 정의 찾다가 아래 내용을 보았는데
utilities to build composite estimator, as a chain of transforms and estimators 라고 하는 것보니
합성적으로 estimate하는 것 같다..
아우 헷갈려
